唯一标识
在实体设计早期,我们将刻意地把关注点放在能体现实体身份唯一性的主要属性和行为上,同时还将关注如何对实体进行查询。另外,我们还会刻意地忽略掉那些次要的属性和行为。
在设计实体时,我们首先需要考虑实体的本质特征,特别是实体的唯一标识和对实体的查找,而不是一开始便关注实体的属性和行为。只有在对实体的本质特征有用的情况下,才加入相应的属性和行为[Evam,p.93]。
那么,首先我们应该怎么做呢?找到多种能够实现唯一标识性的方式是非常重要的,同时我们还应该考虑如何在实体的生命周期内维持它的唯一性。
实体的唯一标识并不见得一定有助于对实体的查找和匹配。将唯一标识用于实体匹配通常取决于标识的可读性。比如,如果系统提供根据人名查找功能,但此时一个Person实体的唯一标识极有可能不是人名,因为存在大量重名的情况。另一方面,如果一个系统提供根据公司税号的查找功能,此时税号便可以作为Company实体的唯一标识,因为政府为每个公司分配了唯一的税号。
值对象可以用于存放实体的唯一标识。值对象是不变(immutable)的,这可以保证实体身份的稳定性,并且与身份标识相关的行为也可以得到集中处理。这样,我们便可以避免将身份标识相关的行为泄漏到模型的其他部分或者客户端中。
以下是一些常用的创建实体身份标识的策略,从简单到复杂依次为:
- 用户提供一个或多个初始唯一值作为程序输入,程序应该保证这些初始值是唯一的。
- 程序内部通过某种算法自动生成身份标识,此时可以使用一些类库或框架,当然程序自身也可以完成这样的功能。
- 程序依赖于持久化存储,比如数据库,来生成唯一标识。
- 另一个限界上下文(2)(系统或程序)已经决定出了唯一标识,这作为程序的输入,用户可以在一组标识中进行选择。
接下来,我们将依次讨论以上策略。通常来说,每一种技术方案都存在副作用,其中之一便出现在将关系型数据库用于对象持久化的时候,这样的副作用将泄漏到领域模型中。在讨论实体的身份标识创建策略时,我们将考虑标识生成的时间、关系型数据的引用标识和ORM在标识创建过程中的作用等。另外,我们还会考虑如何保证唯一标识的稳定性。
用户提供唯一标识
让用户手动地输人对象标识看起来是一种很直接的做法。这时用户将输入一些可识别的数值或符号,或者从一系列已有的标识中选择其中之一,然后创建实体对象。诚然,这是一种非常简单的方法,但是这种方法也可能变得复杂。
复杂性之一便是需要用户自己生成高质量的标识。此时标识可能是唯一的,但却有可能是不正确的。在多数情况下,标识必须是不变的,因此用户不能对标识进行修改。但是情况并不总是如此,有时赋予用户修改标识值的权力是有好处的。例如,如果我们将Forum和Discussion的名字作为唯一标识,那么在发生拼写错误时怎么办,或者用户之后决定采用新的名字又该怎么办?如图5.1所示。要改变这些标识值,我们需要付出多大的代价?虽然用户提供的身份标识看似一种节约成本的做法,但也有可能不是。此时我们可以依赖用户来提供唯一的、正确的并且稳定的对象标识吗?
要避免上述问题,我们需要重新讨论一下设计。开发团队需要采用无故障的方法来保证用户输人的的确是唯一的身份标识。虽然基于工作流的标识审批过程对于高吞吐量的领域来说并没有多大帮助,但是它对于生成具有可读性的身份标识来说却是必需的。如果这种方式生成的标识会在将来继续使用,而工作流也是可能的,那么添加一个额外的阶段来保证身份标识的质量是值得的。

我们通常将一些用户输入作为实体的属性,这些属性可以用于对象匹配,但是我们并不将这样的属性作为唯一身份标识。简单属性可以作为实体状态的一部分,他们更容易修改,在这种情况下,我们需要考虑另外的方法来生成实体的唯一标识。
应用程序生成唯一标识
有很多可靠的方法都可以自动生成唯一标识,但是如果应用程序处于集群环境或者分布在不同的计算节点中,我们就需要额外小心了。有些方法可以生成完全唯一的标识,比如UU1D (Universally Unique Identifier)或者GUID (GloballyUnique Idendfier)。以下是生成唯一标识的另一种方法,其中每一步生成的结果都将添加到最终的文本标识中:
- 计算节点的当前时间,以毫秒记
- 计算节点的IP地址
- 虚拟机(Java)中工厂对象实例的对象标识
- 虚拟机(Java)中由同一个随机数生成器生成的随机数
以上可以产生一个128位的唯一值。通常该唯一值通过一个32字节或36字节的16进制数的字符串来表示。在使用36字节时,我们可以用连字符(-)来连接以上各个步骤所生成的结果,比如f36ab21c-67dc-5274-c642-lde2f4d5e72a。在不用连字符时,该标识即为32字节。但无论如何,这都是一个很大的唯一标识,并且不具有可读性。
在Java世界里,以上方法被标准的UUID生成器所替代了(自从Java 1.5),相应的Java类是java.util.UUlD。该类支持4种不同的唯一标识生成算法,这些算法都基于Leach-Salz变量。使用Java标准API,我们可以简单地生成伪随机的唯一标识:
String rawId = java.util.UUID.randomUUID().toString();
以上代码使用了第4类算法,该算法釆用高度加密的伪随机数生成器,而该生成器又基于java.security.SecureRandom生成器。第3类算法釆用对名字加密的方法,它使用了java.security.MessageDigest类。我们可以通过以下方式生成一个基于名字的UUID:
String rawId = java.util.UUID.nameUUIDFromBytes("Sometext".getBytes()).toString();
另外,我们还可以对所生成的伪随机数进行加密:
SecureRandom randomGenerator = new SecureRandom();
int randomNumber = randomGenerator.nextInt();
String randomDigits = new Integer(randomNumber).toString();
MessageDigest encryptor = MessageDigest.getInstance("SHA-1");
byte[] rawIdBytes = encryptor.digest(randomDigits.getBytes());
接下来,剩下的工作只是将rawIdBytes数组转换成16进制数的字符串表示即可。此时我们可以先将随机数转换成字符串类型,再将该字符串传给UUID的nameUUlDFromBytes()工厂[Gamma et al.]方法。
除此之外,还有另外的身份标识生成工具,比如java.rmi.server.UID和java. rmi.dgc.VMID,但这些工具不及java.util.UUID,这里我们不予讨论。
UUID是一种快速生成唯一标识的方法,它不需要与外界交互,比如持久化机制。即便需要在1秒钟之内多次创建实体,UUID生成器也是可以应付的。对于有性能要求的领域来说,我们可以将UUID实例缓存起来,使其在背后不间断地向缓存中填入新的UUID值。如果缓存中的UUID实例由于服务器重启而丢失,在不同的唯一标识之间是不会存在缺口的,因为所有的标识都是随机的,因此重新向缓存中填入UUID值并不会对系统造成影响。
对于如此大的唯一标识,有时从内存使用的角度来看可能并不实际。这时我们可以采用由持久化机制生成的8字节长标识。或者甚至4字节长的标识都已经足够了。这些方法我们将在下文中讨论。
通常来说,我们并不会在用户界面上显示UUID:
f36ab21c-67dc-5274-c642-lde2f4d5e72a
如果UUID可以隐藏起来,或者我们可以使用可读性的引用技术,那么我们便可以使用完整的UUID。比如,我们可以通过E-mai域者其他消息机制来发送具有URI的超媒体资源。此时,超媒体链接中的文本部分便可以用于隐藏UUID,就像HTML中“\
根据UU1D能够表达实体的唯一程度,我们可以只使用UUID中的其中一部分来标记实体。在聚合(10)边界之内,我们可以将缩短后的标识作为实体的本地标识。本地标识表示在同一个聚合中,一个实体的标识只需要和该聚合中的其他实体区分开来即可。而另一方面,作为聚合根(Aggregate Root)的实体则需要全局的唯一标识。
对于我们自己创建的标识生成器来说,我们依然可以使用UUID的某些部分。比如对于APM-P-08-14-2012-F36AB21C,该25字节的标识表示在敏捷项目管理上下文(APM)中创建的一个Product,创建时间为2012年8月14日。额外的F36AB21C即为UUID的第一部分,该部分用于区分同一天所创建的不同Product。这样的标识一方面满足了可读性要求,一方面又提供了很好的全局唯一性。当然,用户并不是唯一的受益者,当这样的标识从一个限界上下文传到另一个限界上下文时,开发者可以立即识别出实体的出处。对于SaaSOvation来说,我们还可以向标识中加人租户信息。
将这样的标识作为String来维护并不是一个好办法,此时使用一个值对象更加合适:
String rawId = "APM-P-08-14-2012-F36AB21C"; // would be generated
ProductId productId = new ProductId(rawId);
...
Date productCreationDate = productId.creationDate();
客户可以询问标识的细节信息,比如一个Product的创建时间等,这样的信息已经方便地包含在标识中。客户并不需要知道原始的标识格式,此时聚合根Product可以通过creationDate()方法向外界暴露该Product的创建时间,而客户并不需要知道对创建时间的获取细节。
public class Product extends Entity {
private ProductId productId;
...
public Date creationDate() {
return this.productId().creationDate();
}
...
}
我们也可以通过第三方的类库和框架来生产实体的唯一标识。比如Apache Commons项目提供了一个Commons [d组件,该组件提供了5种标识生成器。
有些持久化存储,比如NoSQL的Riak和MongoDB,也可以用于生成唯一标识。通常我们使用HTTP的PUT方法向Riak保存一个对象,此时我们需要提供一个键值:
PUT /riak/bucket/key [object serialization]
但是,在使用POST方法保存对象时却不需要提供键值,此时Riak将自动为对象生成一个唯一标识。此外,我们还需要考虑标识及早生成和延迟生成之间的区别,我们将在本章后续内容中对此进行讨论。
对于程序生成的标识来说,什么样的对象可以作为创建标识的工厂对象呢?对于聚合根的唯一标识,我们可以采用资源库(12)来生成唯一标识:
public class HibernateProductRepository
implements ProductRepository {
...
public ProductId nextIdentity() {
return new ProductId(
java.util.UUID.randomUUID().toString().toUpperCase());
}
...
}
将唯一标识的生成放在资源库中是一种自然的选择。
持久化机制生成唯一标识
将唯一标识的生成委派给持久化机制是有特别的好处的。如果我们向数据库获取一个序列值(Sequence)或递增值,结果总是唯一的。
根据标识的所需范围,数据库可以生成2字节、4字节和8字节的唯一标识。在Java中,2字节整数可以表示32,767种不同的标识值;4字节整数可以表示2,147,483,647种标识值;而一个8字节的整数则可以表示9,223,372,036,854,775,807种不同的标识值。
性能可能是这种方法的一个缺点。从数据库中获取标识比直接从应用程序中生成标识要慢得多。一种解决方法是将数据库序列缓存在应用程序中,比如缓存在资源库中。这固然是一种好的方法,但是如果服务器节点需要重启,那么我们将失去很大一部分标识值区间。如果丢失的区间是不能接受的,又或者你只需要相对较小的标识值(2字节整数),这样的缓存机制便不实用了,并且也没有必要。当然,我们可以找回丢掉的标识值区间,但是这有可能引人新的麻烦。
如果可以使用延迟生成的方式,那么缓存标识便不是什么问题了。以下是如何使用Hibernate和Oracle的序列来生成标识:
<id name="id" type="long" column="product_id">
<generator class="sequence">
<param name="sequence">product_seq</param>
</generator>
</id>
在采用MySQL的自增列时配置如下:
<id name="id" type="long" column="product_id">
<generator class="native"/>
</id>
这种方式的性能是很好的,同时配置Hibernate映射也是简单的。但是这种方式在标识生成时间上可能存在一些不足,对此我们将稍后讨论。本节余下部分将讨论及早生成标识策略。
顺序很重要
有时,标识的生成和赋值时间对于实体来说是重要的。 及早标识生成和赋值发生在持夂化实体之前。 延迟标识生成和賦值发生在持久化实体的时候。
以下资源库支持及早标识生成,它的作用是通过查询来生成下一个可用的 Oracle序列值:
public ProductId nextIdentity() {
Long rawProductId = (Long)
this.session()
.createSQLQuery(
"select product_seq.nextval as product_id from dual")
.addScalar("product_id", Hibernate.LONG)
.uniqueResult();
return new ProductId(rawProductId);
}
由于Hibernate将Oracle生成的序列值映射成了 BigDecimal实例,我们必须通知 Hibernate 将 product_id 转化成 Long 类型。
对于不支持序列的数据库来说,比如MySQL,我们应该怎么办呢? MySQL支持自增列。通常来说,只有在向MySQL中插人数据时,MySQL才会产生自增值。然而,我们依然有办法使MySQL的自增功能像Oracle的序列一样工作:
mysql> CREATE TABLE product_seq (nextval INT NOT NULL);
Query OK, 0 rows affected (0.14 sec)
mysql> INSERT INTO product_seq VALUES (0);
Query OK, 1 row affected (0.03 sec)
mysql> UPDATE product_seq SET nextval=LAST_INSERT_ID(nextval + 1);
Query OK, 1 row affected (0.03 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT LAST_INSERT_ID();
+------------------+
| LAST_INSERT_ID() |
+------------------+
| 1 |
+------------------+
1 row in set (0.06 sec)
mysql> SELECT * FROM product_seq;
+---------+
| nextval |
+---------+
| 1 |
+---------+
1 row in set (0.00 sec)
在MySQL中,我们仓ij建了一个名为product_seq的表。接着向该表中插入了一行数据,此时nextval列中有唯——条记录0。以上两个步骤为Product实体创建了一个模拟序列值生成器。之后的两个步骤展示了如何生成单个序列值。我们通过使nextval列自加1的方式来更新该列--product_seq表中的唯一列。更新语句使用了MySQL的一个函数——LASTJNSERT_ID来增加nextval列中的值。首先执行的是表达式参数,执行结果赋给了nextval列。在LAST_1NSERT_1D()函数中,表达式参数nextval+1保持稳定,当之后的SELECT LAST_INSERT_ID()语句执行时,nextval列中的值将作为结果集返回。最后,作为测试,我们可以使用SELECT *FROM product_seq来保证nextval的当前值就是函数的返回值。
Hibernate 3.2.3使用org.hibernate.id.enhanced.SequenceStyleGenerator来生成序列值,但是它只支持延迟标识生成(当向数据库中插入实体时)。要使资源库支持及早标识生成,我们需要自己创建一个Hibernate或JDBC查询语句。下面是在ProductRepository资源库中实现的nextldentity()方法,该方法为MySQL提供及早标识生成功能:
public ProductId nextIdentity() {
long rawId = -1L;
try {
PreparedStatement ps =
this.connection().prepareStatement(
"update product_seq "
+ "set next_val=LAST_INSERT_ID(next_val + 1)");
ResultSet rs = ps.executeQuery();
try {
rs.next();
rawId = rs.getLong(1);
} finally {
try {
rs.close();
} catch(Throwable t) {
// ignore
}
}
} catch (Throwable t) {
throw new IllegalStateException(
"Cannot generate next identity", t);
}
return new ProductId(rawId);
}
在使用JDBC时,我们没有必要使用另外的查询语句来获取LASTINSERT 1D()函数的执行结果,因为update语句已经为我们做了这件事情了。之后我们从ResultSe冲取出long类型的数值,再用该数值创建一个Productld值对象用来表示实体标识。
另外,我们还可以从Hibernate中直接获得IDBC连接,这是有点痛苦的,但却是可能的:
private Connection connection() {
SessionFactoryImplementor sfi =
(SessionFactoryImplementor)sessionFactory;
ConnectionProvider cp = sfi.getConnectionProvider();
return cp.getConnection();
}
如果没有Connection对象,我们便不能使用PreparedStatement来获取到 ResultSet,当然也不能使用序列了。
在使用Oracle、MySQL和其他数据库的序列功能时,我们可以在插人操作之前创建更加紧凑、更有保证的唯一标识。
另一个限界上下文提供唯一标识
如果另一个限界上下文用于给实体标识赋值,那么我们需要对每一个标识进行查找、匹配和赋值。有关DDD集成方面的知识请参考上下文映射图(3)和集成限界上下文(13)。
其中最重要的是精确匹配。此时用户需要提供一种或多种属性,比如账户、用户名和E-mail地址等,以精确定位需要匹配的结果。
通常来说,匹配的输人是模糊的,这样将导致多个查询结果,此时用户需要手动地进行选择,如图5.2所示。用户输人了模糊的查找信息,通过调用外部限界上下文的API,返回的结果可能是0个、1个或多个匹配对象。接着,用户需要在结果中选择某个特定的对象。所选对象的身份标识将作为本地标识。外部实体的一些额外的属性也有可能被复制到本地实体中。

在这种方式中,对象同步可能是个问题。外部对象的改变将如何影响本地对象呢?我们如何知道所关联的对象已经改变了呢?这个问题可以通过事件驱动架构(4)和领域事件(8)予以解决。本地限界上下文订阅外部系统中的领域事件,当本地上下文接收到外部系统的事件通知时,它将相应地更新本地对象。有时同步事件可能由本地上下文发出,外部系统在接受到该事件时同样会做相应的更新操作。
要达到这样的目的并不容易,但是这样做能够创建出更加具有自治性的系统。在自治系统中,我们可以将对象查找限定在本地对象中。这并不是说将外部对象缓存在本地系统中,而是将外部概念翻译成本地限界上下文中的概念,请参考上下文映射图(3)。
这是最为复杂的标识创建策略。要维护本地实体,我们不但需要考虑由本地领域行为所导致的改变,还需要将外部系统也考虑在内。所以在使用这种策略时,我们应该持保守态度。
标识生成时间
实体唯一标识的生成既可以发生在对象创建的时候,也可以发生在持久化对象的时候。有时我们需要及早地生成实体标识,而有时标识生成时间则不那么重要。在需要考虑标识生成时间时,我们应该知道需要将哪些因素考虑在内。
让我们先考虑一种最简单的情形,此时我们允许在持久化对象时一一即向数据库中插人数据时才生成实体标识,如图5.3所示。客户端只需要初始化一个Product对象,然后将其加人到资源库中。在新建Product时,客户端并不需要实体标识,这是好的,因为此时标识并不存在。只有在该Product被持久化之后,实体标识对于客户端才可用。
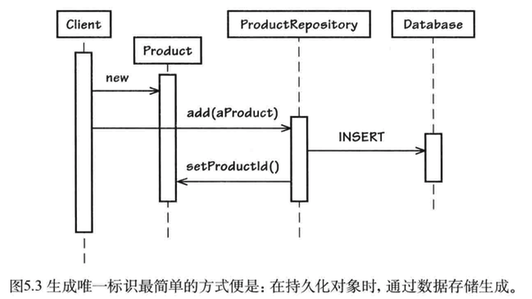
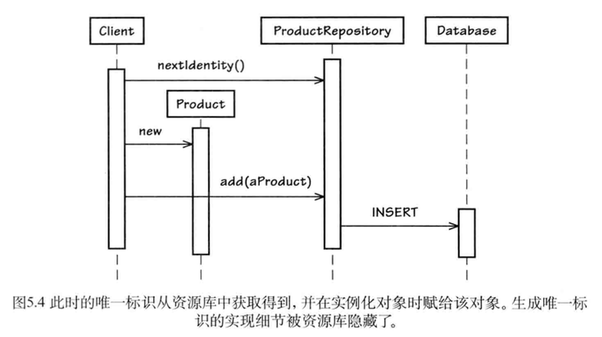
那么,标识创建时间为什么重要呢?考虑一下当客户端需要向外界发布领域事件的情形。在Product初始化完成之后,系统将产生一个领域事件,该事件将保存在事件存储(8)中。最后,所存储的事件将被外部限界上下文中的订阅方所接收。在图5.3中,在客户端将Product加到 ProductRepository之前,领域事件有可能已经被订阅方接收到了。因此,此时领域事件中并不包含新建Product的实体标识。为了正确地创建领域事件,我们应该及早生成实体标识,如图5.4所示。客户端向ProductRepository获取下一个实体标识,然后将该标识作为参数传递给Product的构造函数。
将标识生成延迟到实体持久化时还有另外一个问题。当两个或多个实体需要加人到集合java.util.Set中时,由于此时它们都还没有实体标识,它们的默认标识值都是相等的(比如都为null,或者0,或者1)。如果实体的equalsO方法比较的是实体标识,此时所有新建实体对象都被认为是同一个对象。所以只有第一个对象被保留下来,所有其他对象都被排除在集合之外。这将导致一个严重的bug,并且是一个难以查找的bug。
要避免这样的问题,我们有两种方法。一种方法是及早地生成实体标识,另一种是修改实体的equals()方法,使该方法比较对象的属性,而不是实体标识。如果选择修改equals()方法,此时对实体的实现就像一个值对象一样,同时我们还需要相应地修改hashCode()方法:
public class User extends Entity {
...
@Override
public boolean equals(Object anObject) {
boolean equalObjects = false;
if (anObject != null &&
this.getClass() == anObject.getClass()) {
User typedObject = (User) anObject;
equalObjects =
this.tenantId().equals(typedObject.tenantId()) &&
this.username().equals(typedObject.username()));
}
return equalObjects;
}
@Override
public int hashCode() {
int hashCode =
+ (151513 * 229)
+ this.tenantId().hashCode()
+ this.username().hashCode();
return hashCode;
}
...
}
在一个多租户环境中,Tenantld也被认为是User唯一标识的一部分。如果两个 User 拥有不同的TenantId,那么这两个User一定是不同的。
对于刚才向集合中添加对象的例子来说,我更倾向于及早地生成实体标识这种做法。因为实体的equals()和hashCode()方法最好是基于对象的唯一标识,而不是其他属性。
委派标识
有些ORM工具,比如Hibernate,通过自己的方式来处理对象的身份标识。Hibernate更倾向于使用数据库提供的机制,比如使用一个数值序列来生成实体标识。如果我们自己的领域需要另外一种实体标识,此时这两者将产生冲突。为了解决这个问题,我们需要使用两种标识,一种为领域所使用,一种为ORM所使用,在Hibernate中,这被称为委派标识(Surrogate Identity)。
创建一个委派标识是非常直接的事情一一在实体上创建一个属性来保存委派标识即可。通常来说,委派标识采用long和int类型。同时,我们还需要相应地在数据库中创建一个列来保存该委派标识,并加上主键约束。然后,在实体的Hibernate映射定义中加人\
对外界来说,我们最好将委派标识隐藏起来,因为委派标识并不是领域模型的一部分,而将委派标识暴露给外界可能造成持久化漏洞。虽然一些持久化漏洞是不可避免的,但通过向优秀的开发者学习,我们可以尽量避免这些漏洞。
此时,我们可以使用层超类型(Layer Supertype) [Fowler,P of EAA]:
public abstract class IdentifiedDomainObject
implements Serializable {
private long id = -1;
public IdentifiedDomainObject() {
super();
}
protected long id() {
return this.id;
}
protected void setId(long anId) {
this.id = anId;
}
}
这里的IdentifiedDomainObject便是层超类型,这是一个抽象基类,通过 protected关键字,它向客户端隐藏了委派主键。所有实体都扩展自该抽象基类。在实体所处的模块(9)之外,客户端根本就不用关心id这个委派标识。我们甚至可以将protected换为private。Hibernate既可以通过getter和setter方法来访问属性,也可以通过反射机制直接访问对象属性,故无论是使用protected还是private都是无关紧要的。另外,层超类型还有其他好处,比如支持乐观锁,请参考聚合(10)。
在Hibernate中,我们需要将委派标识id映射到数据库表的某一列。在下面的例子中,User对象的id属性被映射到数据库表中名为id的列上:
<hibernate-mapping default-cascade="all">
<class
name="com.saasovation.identityaccess.domain.model.identity.User"
table="tbl_user" lazy="true">
<id name="id" type="long" column="id" unsaved-value="-1">
<generator class="native"/>
</id>
...
</class>
</hibernate-mapping>
以下是MySQL中对User对象的定义:
CREATE TABLE `tbl_user` (
`id` int(11) NOT NULL auto_increment,
`enablement_enabled` tinyint(1) NOT NULL,
`enablement_end_date` datetime,
`enablement_start_date` datetime,
`password` varchar(32) NOT NULL,
`tenant_id_id` varchar(36) NOT NULL,
`username` varchar(25) NOT NULL,
KEY `k_tenant_id_id` (`tenant_id_id`),
UNIQUE KEY `k_tenant_id_username` (`tenant_id_id`,`username`),
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
第一列,id,即为委派标识。最后一行将id作为表的主键。这里我们可以区分出委派标识和领域标识。其中的两列--tenant_id_id和username 提供了领域标识,它们联合起来形成了一个唯一键k_tenant_id_username。
领域标识不需要作为数据库的主键。这里我们只将委派标识id作为了主键,Hibernate也能正常地工作。
委派主键还可以作为外键与其他表关联,这样提供了引用一致性。这可能出自数据管理上的需求或者为了支持一些工具。引用一致性对于Hibernate来说是重要的,特别是当保存any-to-any (比如1: M)的数据模型时。另外,在从数据库中读取聚合时,引用一致性还支持SQL的联合查询。
标识稳定性
在多数情况下,我们都不应该修改实体的唯一标识,这样可以在实体的整个生命周期中保持标识的稳定性。
我们可以通过一些简单的措施来确保实体标识不被修改。此时,我们可以将标识的setter方法向客户隐藏起来。我们也可以在setter方法种添加逻辑以确保标识在已经存在的情况下不会再被更新,比如可以使用一些断言语句:
public class User extends Entity {
...
protected void setUsername(String aUsername) {
if (this.username != null) {
throw new IllegalStateException(
"The username may not be changed.");
}
if (aUsername == null) {
throw new IllegalArgumentException(
"The username may not be set to null.");
}
this.username = aUsername;
}
...
}
在上面的例子中,username属性是User 实体的领域标识,该属性只能进行一次修改,并且只能在User对象之内修改。setter方法setUsernameO实现了自封装性,并且对客户端不可见。当实体的公有方法自委派给该setter方法时,该方法将对username属性进行检查,看它是否已经被赋值过。如果是,表明该User对象的领域标识已经存在,此时程序将抛出川egalStateException异常。
白板时间
- 对于你当前领域中的一些实体,列出它们的名字。
这些实体的领域标识和委派标识分别是什么?我们是否可以使用更好的标识生成方式?
- 考虑一下,对于不同的实体,哪种标识生成方式是最佳的方式——用户提供、程序生成、持久化机制生成还是另外的限界上下文生成?为什么?
- 再思考一下,对于这些实体,应该采用及早标识生成方式呢,还是延迟生成方式?为什么?
我们应该顿及到标识的稳定性。同时,这也是我们可以进一步改进的地方。
以上这个setter方法并不会阻碍Hibernate对对象的重建,因为对象在创建时. 它的属性都是使用默认值,并且采用无参数构造函数,因此username属性的初始值为null。然后,Hibernate将调用setter方法,由于username属性此时为null,该setter方法得以正确地执行,username属性也将被赋予正确的标识值。
我们可以通过一个测试来保证只能对领域标识做一次修改:
发现实体及其本质特征
public class UserTest extends IdentityTest {
...
public void testUsernameImmutable() throws Exception {
try {
User user = this.userFixture();
user.setUsername("testusername");
fail("The username must be immutable after↵
initialization.");
} catch (IllegalStateException e) {
// expected, fall through 所期待的异常
}
}
...
}
上面的测试向我们演示了User模型的工作方式。同时它验证了:程序不允许对已有的领域标识进行修改,否则将抛出异常。