分层
分层架构模式[Buschmann et al.]被认为是所有架构的始祖。它支持N层架构系统,因此被广泛地应用于Web、企业级应用和桌面应用。在这种架构中,我们将一个应用程序或者系统分为不同的层次。
在分层架构中,我们将领域模型和业务逻辑分离出来,并减少对基础设施、用户界面甚至应用层逻辑的依赖,因为它们不属于业务逻辑。将一个复杂的系统分为不同的层,每层都应该具有良好的内聚性,并且只依赖于比其自身更低的层。[Evans, Ref, P.16]
图4.1所示为一个典型的DDD系统所采用的传统分层架构,其中核心域只位于架构中的其中一层,其上为用户界面层(User Interface)和应用层(ApplicationLayer),其下是基础设施层(Infrastructure Layer)。
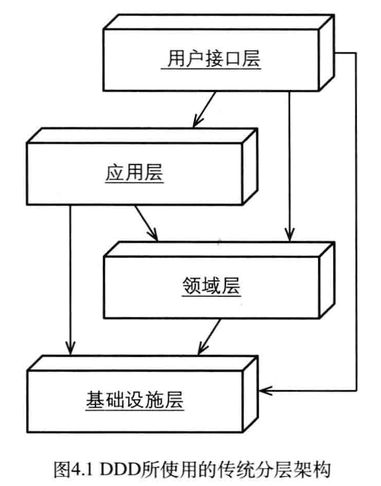
分层架构的一个重要原则是:每层只能与位于其下方的层发生耦合。分层架构也分为几种:在严格分层架构(Strict Layers Architecture)中,某层只能与直接位于其下方的层发生耦合;而松散分层架构(Relaxed Layers Architecture)则允许
任意上方层与任意下方层发生耦合。由于用户界面层和应用服务通常需要与基础设施打交道,许多系统都是基于松散分层架构的。
事实上,较低层也是可以和较高层发生耦合的,但这只局限于采用观察者(Observer)模式或者调停者(Mediator)模式[Gamma et al.]的情况。较低层是绝对不能直接访问较高层的。例如,在使用调停者模式时,较高层可能实现了较低层定义的接口,然后将实现对象作为参数传递到较低层。当较低层调用该实现时,它并不知道实现出自何处。
用户界面只用于处理用户显示和用户请求,它不应该包含领域或业务逻辑。有人可能会认为,既然用户界面需要对用户输人进行验证,那么它就应该包含业务逻辑。事实上,用户界面所进行的验证和对领域模型的验证是不同的。在实体(Entites, 5)中我们会讲到,对于那些粗制滥造的,并且只面向领域模型的验证行为,我们依然应该予以限制。
如果用户界面使用了领域模型中的对象,那么此时的领域对象仅限于数据的渲染展现。在采用这种方式时,可以使用展现模型(Presentation Model, 14)对用户界面与领域对象进行解耦。
由于用户可能是人,也可能是其他的系统,有时用户界面层将采用开放主机服务(13)的方式向外提供API。
用户界面层是应用层的直接客户。
应用服务(Application Services, 14)位于应用层中。应用服务和领域服务 (Domain Services, 7)是不同的,因此领域逻辑也不应该出现在应用服务中。应用服务可以用于控制持久化事务和安全认证,或者向其他系统发送基于事件的消息通知,另外还可以用于创建邮件以发送给用户。应用服务本身并不处理业务逻辑,但它却是领域模型的直接客户。应用服务是很轻量的,它主要用于协调对领域对象的操作,比如聚合(10)。同时,应用服务是表达用例和用户故事(user story)的主要手段。因此,应用服务的通常用途是:接收来自用户界面的输人参数,再通过资源库(12)获取到聚合实例,然后执行相应的命令操作,比如:
@Transactional
public void commitBacklogItemToSprint(
String aTenantId, String aBacklogItemId, String aSprintId) {
TenantId tenantId = new TenantId(aTenantId);
BacklogItem backlogItem =
backlogItemRepository.backlogItemOfId(
tenantId, new BacklogItemId(aBacklogItemId));
Sprint sprint = sprintRepository.sprintOfId(
tenantId, new SprintId(aSprintId));
backlogItem.commitTo(sprint);
}
如果应用服务比上述功能复杂许多,这通常意味着领域逻辑已经渗透到应用服务中了,此时的领域模型将变成贫血模型。因此,最佳实践是将应用层做成很薄的一层。当需要创建新的聚合时,应用服务应该使用工厂(Factory, 11)或聚合的构造函数来实例化对象,然后采用资源库对其进行持久化。应用服务还可以调用领域服务来完成和领域相关的任务操作,但此时的操作应该是无状态的。
当领域模型用于发布领域事件(Domain Events, 8)时,应用层可以将订阅方注册到任意数量的事件上,这样的好处是可以对事件进行存储和转发。同时,领域模型只需要关注自己的核心逻辑;领域事件发布器(Domain EventPublisher, 8)也可以保持轻量化,而不用依赖于消息机制的基础设施。
我们将在另外的章节中讲到领域模型对业务逻辑的处理。然而,在传统的分层架构中,却存在着一些与领域相关的挑战。在分层架构中,领域层或多或少地需要使用基础设施层。这里我并不是说核心的领域对象会直接参与其中,而是说领域层中的有些接口实现依赖于基础设施层。
比如,资源库接口的实现需要基础设施层提供的持久化机制。那么,如果我们将资源库接口直接实现在基础设施层会怎样呢?由于基础设施层位于领域层之下,从基础设施层向上引用领域层则违反了分层架构的原则。遵从分层架构原则并不意味着领域对象需要与基础设施层发生直接耦合,此时我们可以采用模块(9)的方式来隐藏技术实现细节:
com.saasovation.agilepm.domain.model.product.impl
在模块(9)章节中,我们会讲到,MongoProductRepository将被放置在以上的包中。然而,这并不是解决问题的唯一办法,我们还可以将资源库的接口实现放在应用层中,这样便可以维持分层架构的原则,如图4.2所示。
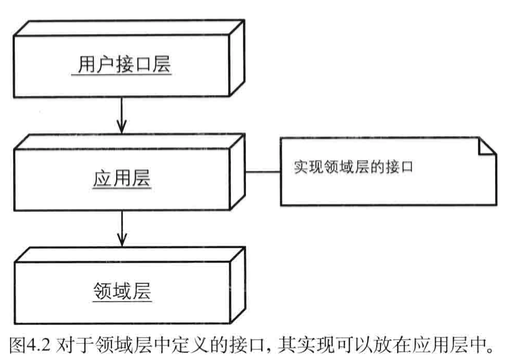
还有更好的方法,请参考下文的“依赖倒置原则”。
在传统的分层架构中,基础设施层位于底层,持久化和消息机制便位于该层中。这里的消息包含了消息中间件所发的消息、基本的电子邮件(SMTP)或者文本消息(SMS)。可以将基础设施层中所有的组件和框架看作是应用程序的低层服务,较高层与该层发生耦合以重用技术上的基础设施。即便如此,我们依然应该避免核心的领域模型对象与基础设施层发生直接耦合。
SaaSOvation的开发团队发现.将基础设施层放在最底层是存在缺点的。比如.此时领域层中的一些技术实现是令人头疼的.因为他们违背了分层架构的基本原则。再者.很难为这样的实现编写测试。他们应该如何应对呢?
如果我们调整一下分层架构中各层的顺序,结果会有所改观吗?
依赖倒置原则
有一种方法可以改进分层架构--依赖倒置原则(Dependency Inversion Principle,DIP),它通过改变不同层之间的依赖关系达到改进目的。依赖倒置原则由Robert C. Martin提出[Martin,DIP],正式的定义为:
高层模块不应该依赖于低层模块,两者都应该依赖于抽象。 抽象不应该依赖于细节,细节应该依赖于抽象。
根据该定义,低层服务(比如基础设施层)应该依赖于高层组件(比如用户界面层、应用层和领域层)所提供的接口。在架构中采用依赖倒置原则有很多种表达方式,这里我们将采用图4.3中的方式。

图4.3在使用依赖倒置原则时的一种分层方式。我们将基础设施层放在所有层的最上方,这样它可以实现所有其他层中定义的接口。
依赖倒置原则真的可以支持所有的层吗?
有人认为,在依赖倒置原则中只存在两层,一层位于最上方,一层位于最下方。上方层将实现由下方层定义的抽象接口。按此对图4.3进行调整,基础设施层将位于最上方,用户界面层、应用层和领域层将作为相同的一层,并且位于下方。对此,你可以保留自己的意见。不要担心,我们将在六边形[Cockburn]或端口和适配器架构中对此做详细讲解*
对于图4.3中的架构,我们可以在领域层中定义资源库接口,然后在基础设施层中实现该接口:
package com.saasovation.agilepm.infrastructure.persistence;
import com.saasovation.agilepm.domain.model.product.*;
public class HibernateBacklogItemRepository
implements BacklogItemRepository {
...
@Override
@SuppressWarnings("unchecked")
public Collection<BacklogItem> allBacklogItemsComittedTo(
Tenant aTenant, SprintId aSprintId) {
Query query =
this.session().createQuery(
"from -BacklogItem as _obj_ "
+ "where _obj_.tenant = ? and _obj_.sprintId = ?");
query.setParameter(0, aTenant);
query.setParameter(1, aSprintId);
return (Collection<BacklogItem>) query.list();
}
...
}
我们应该将关注点放在领域层上,采用依赖倒置原则,使领域层和基础设施层都只依赖于由领域模型所定义的抽象接口。由于应用层是领域层的直接客户,它将依赖于领域层接口,并且间接地访问资源库和由基础设施层提供的实现类。应用层可以采用不同的方式来获取这些实现,包括依赖注入(DependencyInjection)、服务工厂(Service Factory)和插件(Plug In)[Fowler, P of EAA]。本书的所有例子都采用Spring提供的依赖注人功能,有时也会采用DomainRegistry类所提供的服务工G事实上,DomainRegistry也是使用Spring来完成对bean的查找的,这些bean实现了由领域模型所定义的接口,包括资源库和领域服务。
有趣的是,当我们在分层架构中采用依赖倒置原则时,我们可能会发现,事实上已经不存在分层的概念了。无论是高层还是低层,它们都只依赖于抽象,好像把整个分层架构给推平了一样。如果我们将分层架构推平,再向其中加人一些对称性会变得如何?请继续往下读。