为什么我们需要DDD
事实上,在前面我已经提到了一些应该采用DDD的原因。冒着有悖DRY原则 (Don’t repeat yourself,不要做重复的事情)的风险,我重新说说我们需要采用DDD的原因。
- 使领域专家和开发者在一起工作,这样开发出来的软件能够准确地传达业务规则。当然,对于领域专家和开发者来说,这并不表示单单地包容对方,而是将他们组成一个密切协作的团队。
- “准确传达业务规则”的意思是说,此时的软件就像如果领域专家是编码人员时所开发出来的一样。
- 可以帮助业务人员自我提高。没有任何一个领域专家或者管理者敢说他对业务已经了如指掌了,业务知识也需要一个长期的学习过程。在DDD中,每个人都在学习,同时每个人又是知识的贡献者。
- 关键在于对知识的集中,因为这样可以确保软件知识并不只是掌握在少数人手中。
- 在领域专家、开发者和软件本身之间不存在“翻译”,意思是当大家都使用相同的语言进行交流时,每人都能听懂他人所说。
- 设计就是代码,代码就是设计。设计是关于软件如何工作的,最好的编码设计来自于多次试验,这得益于敏捷的发现过程。
- DDD同时提供了战略设计和战术设计两种方式。战略设计帮助我们理解哪些投入是最重要的;哪些既有软件资产是可以重新拿来使用的;哪些人应该被加到团队中?战术设计则帮助我们创建DDD模型中各个部件。
就像其他高回报率的投人一样,DDD需要我们在时间和精力上都有所投人。但是,考虑到我们在开发软件的过程中经常遇到的各种问题和挑战,这样的投入是值得的。
难以捉摸的业务价值
开发能够传递真正业务价值的软件和开发普通的软件是不同的。具有真正业务价值的软件能够很好地符合业务战略,并且可以将竞争优势融合到解决方案中。此时的软件并不是关于技术的,而是关于业务的。
业务知识从来就没有被集中过。开发团队必须在多方之间权衡各种需求,并确定其中的优先级。同时,团队成员的技能也是良莠不齐的。在获得所有的信息之后,团队所面临的问题在于:如何确定某种需求确实能够传递真正的业务价值?还有,我们如何去发现并暴露出这些业务价值,如何安排它们之间的优先级,并且如何实现它们?
在开发过程中,最大的鸿沟之一便存在于领域专家和开发者之间。通常来说,领域专家将关注点放在交付业务价值上,而开发者则将注意力放在技术实现上。当然,并不是说开发者的动机是错误的,而是说开发者的眼光被自然而然地吸引到了实现层面上。即便让领域专家和开发者一同工作,他们之间的协作也只是表面的,这时在所开发的软件中便产生了一种映射:将业务人员所想的映射到开发者所理解的。这样一来,软件便不能完全反映出领域专家的思维模型。随着时间的推移,这种鸿沟将增加软件的开发成本。而随着开发者转到其他项目或者离职,本应该驻留在软件中的领域知识也就丢失了。
另一个问题发生在当多个领域专家之间存在分歧的时候。这是很有可能发生的,因为每个专家只是熟悉某个或者某些特定的领域。另外,在某个领域里找不到真正的专家也是可能的,此时,有人可能对该领域有所了解,但是他更像一个业务分析员。这些问题将导致相互矛盾的软件模型。
更糟的是,软件的技术实现可能错误地改变软件的业务规则。比如,erp软件通常需要修改业务操作以满足某个特定用户的需求,因此ERP的成本不能单以使用许可和维护费用来计算,对业务规则的修改所产生的成本远远大于前两者。另外一个相似的例子是当开发团队将业务需求翻译成软件功能的时候。这对于业务、用户和合作方来说都是一笔很大的成本。还有,技术上的翻译和解释是没有必要的,并且在使用适当开发方式的情况下是可以避免的。解决方案才是主要的投入。
DDD如何帮助我们
DDD作为一种软件开发方法,它主要关注以下三个方面:
DDD将领域专家和开发人员聚集到一起,这样所开发的软件能够反映出领域专家的思维模型。这并不意味这我们将精力都花在了对“真实世界”的建模上,而是交付最具业务价值的软件。有时在实用和理想之间存在冲突,根据它们的互异程度,在DDD中我们将选择实用性。
领域专家将和开发人员一起创建一套适用于领域建模的通用语言。通用语言必须在全队范围之内达成一致,所有成员都使用通用语言进行交流,通用语言也是对软件模型的直接反映。请注意,虽然团队中同时包含领域专家和开发人员,但并不是“我们”和“他们”的关系,团队中只有“我们”的概念。
通用语言也有助于促使原本存在分歧的领域专家们达成一致意见。此外,通过将领域知识传达给所有的团队成员,包括开发人员,整个团队也将更具凝聚力。我们甚至可以认为,这是每个公司都应该有的对于知识型工作者的起码训练。
DDD关注业务战略。虽然说战略(Strategic)设计自然地包含了战术设计,但是战略设计关注更多的则是业务的战略方向。它帮助我们定义不同团队之间的组织关系,并在这些关系有可能导致项目失败的时候提供早期预警。DDD的战略设计用于清楚地界分不同的系统和业务关注点,这样可以保护每个业务层面的服务。更进一步,这将指引我们如何实现面向服务架构(service-oriented architecture) 或者业务驱动 (business-driven architecture) 架构。
通过使用战术设计建模工具,DDD满足了软件真正的技术需求。这些战术设计工具使开发人员能够按照领域专家的思维模型开发软件。同时,所开发出来的软件是可测试的,能够尽量避免错误,能执行服务层面协议(Service-Level Agreement, SLA),具有很好的伸缩性,并且允许分布式计算。DDD的最佳实践同时包含了高层的架构性实践和底层设计实践,关注业务规则和数据不变性,并且可以对业务规则起到保护作用。
通过这种方式开发软件,你和你的团队将能成功地交付真正的业务价值。
处理领域复杂性
在使用DDD时,我们首先希望将它应用在最重要的业务场景下。对于那些可以轻易替换的软件来说,你是不会有所投入的。相反,值得你投人的是那些重要的、复杂的东西,因为这些东西将为你带来可观的回报。正因如此,我们将这样的模型命名为核心域(CoreDomain, 2),而那些相对次要的称为支撑子域(Supporting Subdomain, 2)。那么现在,我们需要搞明白的是,“复杂”到底是什么意思?
DDD的作用是简化,而不是复杂化
在使用DDD时,我们应该采用最简单的方式对复杂领域进行建模,而不是使问题变得更加复杂。
不同的业务领域对于复杂的定义是不一样的。另外,不同的公司所面临的挑战不一样;成熟度不一样;软件开发能力也不一样。因此,与其去定义什么是复杂的,还不如定义什么是重要的。这时,你的团队和管理层应该做出决定:你们开发的软件系统是否值得做出DDD投入。
DDD计分卡:使用表1.1来决定你的项目是否值得做出DDD投人。如果你的项目情况在某行的描述范围之内,那么请在右边的列中记上相应的分数,最后将这些分数相加得到总分。如果得分为7分或者以上,那么,你应该考虑使用DDD了。
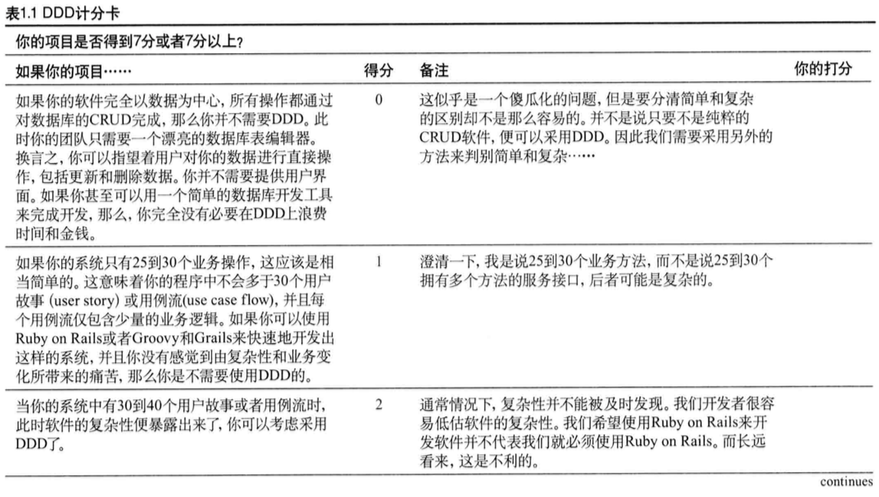
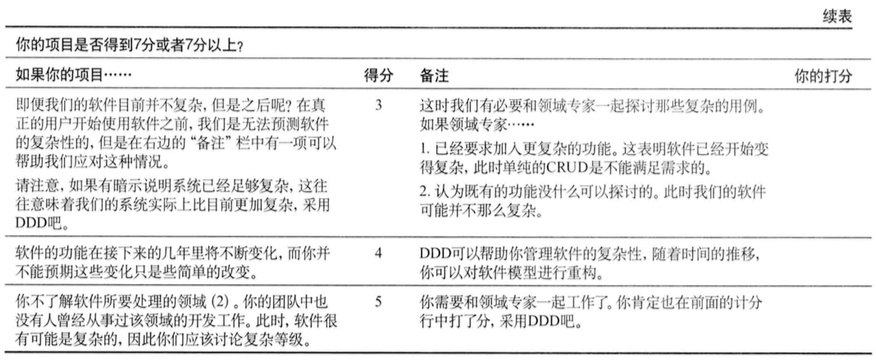
通过对以上DDD计分卡打分,我们可以得出以下结论:
- 当我们在复杂性问题上犯错时,我们很难轻易地扭转颓势。 这意味着我们应该在项目计划早期便对简单性和复杂性做出判断,这将为我们节约很多时间和开销,并免除很多麻烦。
- 一旦我们做出了重要的架构决策,并且已经在该架构下进行了深入地开发,通常我们也被綁定在这个架构下了,所以在决定时一定要慎重。
如果你对以上几点产生了共鸣,表明你已经在认真地思考问题了。
贫血症和失忆症
贫血症严重危害着人类健康,并且伴随有危险的副作用。当贫血领域对象(Anemic Domain Object)[Fowler, Anemic]被首次提出来时,它并不是一个博得赞美的词汇,它描述的是一个缺少内在行为的领域对象。奇怪的是,人们对于贫血领域对象的态度褒贬不一。问题在于,多数开发者认为这样的领域对象是正常的’他们并没有意识到这是一个严重的问题。
你是否想知道你所建模型的健康状况呢?如果你突然患上了技术上的“忧郁症”,这里你可以做个自我检查。你可能心情愉说,也可能无比恐惧。通过表1.2中的步骤开始检查吧。

如果你对以上两个问题的回答都是“No”,表明你的领域对象是健康的。
如果都是“Yes”,表明你的领域对象已经病得不轻了,这便是贫血对象。好消息是,你是可以获得帮助的,继续往下读吧。
如果你对其中一个回答“Yes”,而另一个回答“No”,你可能是在自欺或者患上了由贫血症导致的神经系统紊乱,此时你应该怎么办呢?回到第一个问题重新来一遍,不要着急,要确保对两个问题都回答“Yes”。
正如[Fowler, Anemic]所说,贫血领域对象是不好的,因为你花了很大的成
本来开发领域对象,但是从中却获益甚少。比如,由于存在对象-关系阻抗失配 (Object-Relational Impedance),开发者需要将很多时间花在对象和数据存储之间的映射上。这样的代价太大,而收益太小。我得说,你所说的领域对象根本就不是领域对象,而只是将关系型数据库中的模型映射到了对象上而已。这样的领域对象更像是活动记录(Active Record) [Fowler, P of EAA],此时你可以对架构做个简化,然后使用事务脚本(Transaction Script) [Fowler, P of EAA]进行开发。
为什么会有贫血领域对象
如果说贫血领域对象是由设计不当造成的,为什么还有如此多的人认为他们的领域对象是健康的呢?其中一个原因是:贫血领域对象反映了一种自然的过程式的编程风格,但我并不认为这是首要原因。软件业中有很多开发者都是学着示例代码做开发的,这并不是什么坏事,只要示例代码本身是好的。然而,通常情况是,示例代码只是用尽可能简单的方式来展示某个特定的概念或者API特性,而并不强调要遵循多好的设计原则。一些极度简化的示例代码总是包含了大量的getter和setter,于是这些getter和setter随着示例代码每天被程序员们原封不动地来回复制。
还有历史的影响。Microsoft的Visual Basic对我们现在的软件开发产生了很大的影响。我并不是说Visual Basic是门不好的语言和集成开发环境(IDE),因为它的确是种高效的开发方式,并且在某些方面对软件开发产生过正面的影响。当然,有些人可能会拒绝Visual Basic的直接影响,但是最终它却间接地影响着每一个程序员。请注意表1.3中的时间线。
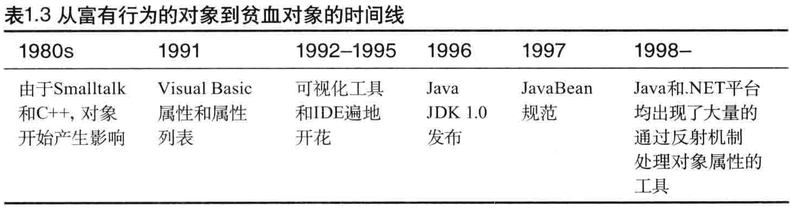
这里,我想谈及的是对象属性和属性列表带来的影响。对象属性和属性列表都得益于getter和setter的支持,而Visual Basic的窗体设计器将getter和setter变得过于流行了。你需要做的只是将自定义控件拖到窗体上,然后编辑控件的属性列表,大功告成,一个功能完备的窗体程序开发完毕。如果直接采用C语言的Windows API来开发相同的窗体,可能需要几天时间,而采用Visual Basic只是几分钟的事情。
那这和贫血领域对象有什么关系呢? javaBean标准最早是用来辅助java的可视化设计工具的,旨在将Microsoft的Active X开发方式带到Java平台。Java此举希望开创一个第三方自定义控件市场,就像Visual Basic—样。此后不久,几乎所有的框架和类库都涌入到了 JavaBean潮流中,其中包括Java本身的SDK/JDK和第三方类库,比如Hibernate。在.NET平台推出之后,这样的趋势还在继续。
有趣的是,在早期的Hibernate版本中,所有需要持久化的领域对象都必须暴露公有的getter和setter,不管是对于简单类型的属性,还是对复杂类型皆如此。这意味着,即便你希望将自己的POJO (Plain Old Java Object)设计成富含行为的对象,你都必须将对象的内部暴露给Hibernate以保存或重建对象。诚然,你可以隐藏公有的JavaBean接口,但是多数开发者都懒得这样做,或者甚至都不知道为什么应该这么做。
我应该考虑在DDD中使用对象-关系映射(Object-RelationalMapping, ORM)吗?
前面主要是从历史的角度对Hibernate进行了批评。现在,Hibernate已经不需要对象暴露getter和setter了,它甚至可以对对象属性进行直接操作。我将在后面的章节中讲到在使用Hibernate或其他持久化机制时如何避免贫血对象。
此外,多数的Web框架依然只支持JavaBean规范。如果你想将一个Java对象显示在网页上,该Java对象最好是支持JavaBean规范的。如果你想将HTML表单中的数据传到一个Java对象中,该Java对象也最好是支持JavaBean规范的。
市场上的几乎每种框架都要求对象暴露公有属性。这样一来,多数开发者只能被动地接受那些贫血对象。于是我们便到了“到处都是贫血对象”的地步。
看看贫血对象都对你的模型做了些什么
好吧,我们同意这已经是烦人的即成事实。但是这些无处不在的贫血对象和失忆症又有什么关系呢?当你在阅读一个贫血领域对象的示例代码时,比如应用服务(4,14)中的事务脚本,你通常会看到类似如下的代码片段:
@Transactional
public void saveCustomer(
String customerId,
String customerFirstName, String customerLastName,
String streetAddress1, String streetAddress2,
String city, String stateOrProvince,
String postalCode, String country,
String homePhone, String mobilePhone,
String primaryEmailAddress, String secondaryEmailAddress) {
Customer customer = customerDao.readCustomer(customerId);
if (customer == null) {
customer = new Customer();
customer.setCustomerId(customerId);
}
customer.setCustomerFirstName(customerFirstName);
customer.setCustomerLastName(customerLastName);
customer.setStreetAddress1(streetAddress1);
customer.setStreetAddress2(streetAddress2);
customer.setCity(city);
customer.setStateOrProvince(stateOrProvince);
customer.setPostalCode(postalCode);
customer.setCountry(country);
customer.setHomePhone(homePhone);
customer.setMobilePhone(mobilePhone);
customer.setPrimaryEmailAddress(primaryEmailAddress);
customer.setSecondaryEmailAddress (secondaryEmailAddress);
customerDao.saveCustomer(customer);
}
刻意保持例子的简单
必须得承认,以上代码并不表示一个有趣的领域,但是却帮助我们看到了一个欠妥的设计,我们可以将其重构成更好的糢型。这里我们关注的并不是如何保存Customer数据,而是如何向模型中添加业务价值,即便就这个例子本身来说意义并不大。
以上代码完成了什么功能呢?事实上,以上代码的功能是相当强大的。不管一个Customer是新建的还是先前存在的,不管是Customer的名字变了还是他搬进了新家;不管是他的家用电话号码变了还是他有了新的移动电话;也不管他是改用Gmail还是有了新的E-mail地址,这段代码都会保存这个Customer。哇,好厉害的方法啊!
情况真是这样的吗?其实,我们并不知道saveCustomer()方法的业务场景。为什么一开始会创建这个方法?有人知道它的本来意图吗,还是它原本就是用来满足不同业务需求的?几周或几个月之后,我们便将这些忘得一干二净了。你不相信?那请看看该方法的下一个版本:
@Transactional
public void saveCustomer(
String customerId,
String customerFirstName, String customerLastName,
String streetAddress1, String streetAddress2,
String city, String stateOrProvince,
String postalCode, String country,
String homePhone, String mobilePhone,
String primaryEmailAddress, String secondaryEmailAddress) {
Customer customer = customerDao.readCustomer(customerId);
if (customer == null) {
customer = new Customer();
customer.setCustomerId(customerId);
}
if (customerFirstName != null) {
customer.setCustomerFirstName(customerFirstName);
}
if (customerLastName != null) {
customer.setCustomerLastName(customerLastName);
}
if (streetAddress1 != null) {
customer.setStreetAddress1(streetAddress1);
}
if (streetAddress2 != null) {
customer.setStreetAddress2(streetAddress2);
}
if (city != null) {
customer.setCity(city);
}
if (stateOrProvince != null) {
customer.setStateOrProvince(stateOrProvince);
}
if (postalCode != null) {
customer.setPostalCode(postalCode);
}
if (country != null) {
customer.setCountry(country);
}
if (homePhone != null) {
customer.setHomePhone(homePhone);
}
if (mobilePhone != null) {
customer.setMobilePhone(mobilePhone);
}
if (primaryEmailAddress != null) {
customer.setPrimaryEmailAddress(primaryEmailAddress);
}
if (secondaryEmailAddress != null) {
customer.setSecondaryEmailAddress (secondaryEmailAddress);
}
customerDao.saveCustomer(customer);
}