理解限界上下文
不要忘了,限界上下文是一个显式的边界,领域模型便存在于这个边界之内。 领域模型把通用语言表达成软件模型。创建边界的原因在于,每一个模型概念,包括它的属性和操作,在边界之内都具有特殊的含义。如果你是建模团队中的一员,你便应该知道这些概念的确切含义。
限界上下文是显式的,充满语义的
限界上下文是一个显式边界,领域糢型便存在于边界之内。在边界内,通用语言中的 所有术语和词组都有特定的含义,而模型需要准确地反映通用语言。
在很多情况下,在不同模型中存在名字相同或相近的对象,但是它们的意思却 不同。当模型被一个显式的边界所包围时,其中每个概念的含义便是确定的了。因此,限界上下文主要是一个语义上的边界,我们应该通过这一点来衡量对一个限界上下文的使用正确与否。
有些项目试图创建一个“大而全”的软件模型,其中每个概念在全局范围之内 只有一种定义。这是一个陷阱。首先,要使所有人都对某个概念的定义达成一致几乎不可能。有些项目太庞大,太复杂,以致于你根本无法将所有的利益相关方聚集到一起,更不用提达成一致了。即便是那些规模相对较小的公司,要维持一个全局性的,并且经得住时间考验的概念定义也是困难的。因此,最好的方法是去正视这种不同,然后使用限界上下文对领域模型进行分离。
限界上下文并不旨在创建单一的项目资产,它并不是一个单独的组件、文档、或者框图1、因此,它并不一个是JAR或者DLL,但是这些可以用来部署限界上下文,我们会在后面讲到。
1. 目前你可以用框图来表示限界上下文,但是框图并不是限界上下文本身。 ↩
让我们来看看一个账户(Account)模型在银行上下文(Banking Context)和文学上下文(Literary Context)中的不同,如表2.1所示。

在图2.5中,光凭名字我们根本无法区分两个账户的意思。只有通过它们所在 的限界上下文我们才能看出它们之间的区别。
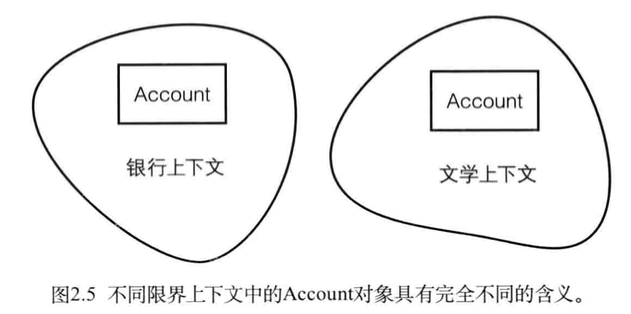
这两个上限界上下文可能并不属于同一个领域,这里我只是想说明:上下文才是王道。
上下文才是王道
上下文才是王道,特别是在实施DDD的时候。
在金融领域,我们经常谈到证券(security)。证券交易管理委员会(Securities and Exchange Commission, SEC)限制证券只能和股票(equities) —起使用。现在让我们考虑这种情况:期权合同(futures contract)作为一种商品,它并不被SEC所管理。然而,有些金融公司却将期权当作一种证券,并且用标准类型(Standard Type, 6) Futures来表示。
这是表示期权的最好方式吗?这取决于它所处的领域。有人认为期权显然是一种证 券,另有人则持反面意见。上下文同时也是具有文化属性的。对于一个经营期权的公司,在通用语言中以证券来表示期权在文化上是合理的。
在通常情况下,我们所面对的都是一些区别甚小的概念定义。原因在于:在一 个上下文中,团队通常根据通用语言来命名某个概念。我们并不会随意地命名一个概念以刻意地保持与其他上下文的不同。比如两个银行上下文,一个用于支票账户,另一个用于储蓄账户2。在支票上下文(Checking Context)中,我们不必使用支票账户(Checking Account);在储蓄上下文(Saving Context)中我们也不必使用储蓄账户(Saving Account)。两个概念都可以使用账户(Account)来表示,因为限界上下文已经对此做了区分。当然,我们并没有规定不能使用更具体的名字,这只是团队自己的选择而已。
2. 这里假设支票账户和储蓄账户分别对应两个不同的限界上下文。 ↩
当需要集成时,我们必须在不同的限界上下文之间进行概念映射。在DDD中, 这可能是复杂的,因此我们应该特别留意。在上下文边界之外,我们通常不会使用该上下文之内的对象实例,但是不同上下文中彼此关联的对象可能共享一些状态。
再看另一个例子,该例中同一个领域的不同限界上下文使用了相同的概念名。 考虑一个图书出版机构,它需要处理图书生命周期的不同阶段。粗略地讲,我们可以认为这些不同的阶段对应于以下不同的上下文环境:
- 概念设计,计划出书
- 联系作者,签订合同
- 管理图书的编辑过程
- 设计图书布局,包括插图
- 将图书翻译成其他语言
- 出版纸质版或电子版图书
- 市场营销
- 将图书卖给销售商或直接卖给读者
- 将图书发送给销售商或读者
在以上所有阶段中,我们可以用一个单一的概念对图书建模吗?显然不行。在 每个阶段中,“图书”都有不同的定义。一本书只有在和作者签订了合同之后才能拥有书名,而书名可能在编辑过程进行修改。在编辑过程中,图书包含了一系列的稿件,其中包括注释和校正等,之后会有一份最终稿件。页面布局由专门的图形设计师完成。图书印刷方使用页面布局和封面板式印制图书。市场营销员不需要编辑稿件或图书印制成品,他们可能只需要图书的简介即可。对于图书的售后物流,我们需要的是图书的标识码、物流目的地、数目、尺寸和重量等。
想象一下,如果我们使用一个单一模型来处理所有这些阶段会发生什么?概念 混淆、意见分歧和争论是不可避免的,我们所交付的软件也没有多大价值。即便有时我们可能会得到一个正确的公共模型,但这种模型并不具有持久性。
为了解决这个问题,我们应该为每个阶段创建各自的限界上下文。在每个限界 上下文中,都存在某种类型的图书(Book)。在几乎所有的上下文中,不同类型的图书对象将共享一个身份标识(identity),这个标识可能是在概念设计阶段创建的。
然而,不同上下文中的图书模型却是不同的。当某个限界上下文的团队说到图书 时,该“图书”正好能表示该上下文所需要的意思。如此这般,我们根据不同的需求很自然地创建了不同类型的图书,但这并不表示这种建模过程就是可以轻易达到的。不管如何,在使用显式限界上下文的情况下,我们可以定期地、增量式的交付软件,同时所交付的软件又能满足特定的业务需求。
这里,让我们快速浏览一下SaaSOvation的协作团队是如何解决图2.3中的建模问题的。
前面已经提到,协作上下文的领域专家并没有从用户和权限的角度去描述协 作工具的使用者,而是以他们所扮演的角色进行描述,比如作者、拥有者、参与者和主持者等。个人的联系方式可能出现在该上下文中,但我们并不需要所有的联系信息。另一方面,只有在身份与访问上下文中我们才会谈及到用户。在该上下文中,用户对象包含了某人的用户名和一些详细信息,其中便包含了该用户的联系方式。
然而,我们也不会凭空创建一个Author对象,因为每一个协作者 (collaborator)都需要事先进行资格认证才能使用协作软件。在身份与访问上下文中,我们将验证拥有某种角色的用户是否存在,验证信息将随着请求传给身份与访问上下文。要创建一个协作对象,比如一个Moderator,我们将使用对应用户的一部分属性,另外还需要一个角色名。如何从另一个限界上下文中获取对象状态(本书后续章节将对此做详细讲解)并不重要,重要的是,两个不同的概念既有相似之处,又有不同之处,不同之处由限界上下文决定。在图2.6中,一个限界上下文中的User和Role信息被另一个限界上下文用来创建Moderator对象。

白板时间
- 在你自己的领域中,看看你能否在不同的限界上下文中识别出那些区别微 小的概念。
- 看看这些概念是不是得到了正确的分离,或者你只是简单地将相应代码从 一个地方复制到另一个地方。
通常情况下,你是可以识别出那些概念分离正确的情况的,因为有些相似的对象拥有不 同的属性和行为,此时我们可以认为上下文边界的划分是合理的。然而,如果你在不同的限界上下文中看到了完全相同的对象,这通常意味着你的糢型是错误的,除非这些限界上下文使用了共享内核(Shared Kernel, 3)
限界上下文不仅仅只包含模型
一个限界上下文并不是只包含领域模型。诚然,模型是限界上下文的主要“公 民”。但是,限界上下文并不只局限于容纳模型,它通常标定了一个系统、一个应用程序或者一种业务服务3。有时,限界上下文所包含的内容可能比较少,比如,一个通用子域便可以只包含领域模型。
3. 应当承认,对于系统、应用程序和业务服务的含义,业界并没有达成一致。但是,一般来讲,我倾向于将它们表示成一系列用于实现业务用例的复杂组件。 ↩
当模型驱动着数据库Schema的设计时,此时的数据库Schema也应该位于 该模型所处的上下文边界之内。这是因为数据库Schema是由建模团队设计、开发并维护的。这也意味着数据库中表和列的名字应该和模型的名字保持一致。比如,对于模型中包含的Backlogltem类,它拥有值对象属性backlogltemld和businessPriority:
public class Backlogltem extends Entity {
...
private BacklogItemld backlogltemld;
private BusinessPriority businessPriority;
...
}
在数据库中对应的表定义为:
CREATE TABLE `tbl_backlog_item` (
...
`backlog_item_id_id` varchar(36) NOT NULL,
`business_priority_ratings_benefit` int NOT NULL,
`business_priority_ratings_cost` int NOT NULL,
`business_priority_ratings_penalty` int NOT NULL,
`business_priority_ratings_risk` int NOT NULL,
...
) ENGINE=InnoDB;
另一方面,如果数据库Schema已经存在,或者另有一个专门的数据建模团队 要求有别于模型的数据库Schema设计,此时的Schema便不能和模型位于同一个限界上下文中了。
如果用户界面(User Interface, 14)被用于渲染模型,并且驱动着模型的行为设计时,同样,该用户界面也应该属于模型所在的上下文边界之内。但是,这并不 表示我们应该在用户界面中对领域进行建模,因为这样将导致贫血领域对象。我们应该拒绝使用智能UI反模式(Smart Ul Anti-Pattern)[Evans],或者任何试图将领域概念带到领域模型之外的举措。
通常情况下,一个系统/应用程序的使用者并不只是人,还可能是另外的计算 机系统。系统中有可能存在诸如Web服务(Web services)之类的组件。我们也可以使用REST资源来与模型交互,此时的REST资源即被称为开放主机服务(OpenHost Service, 3,13)。或者,我们可以使用SOAP或消息服务端点。在以上所有情况中,那些面向服务的组件都应该位于上下文边界之内。
用户界面和面向服务端点都会将操作委派给应用服务(14)。应用服务包含了 不同类型的服务,比如安全和事务管理等。对于模型来说,应用服务扮演的是一种门面模式Facade [Gamma etal.]。同时,应用服务还具有任务管理功能,它将来自用例流(Use Case Flow)的请求转换成领域逻辑的执行流。应用服务也是位于上下文边界之内的。
更多关于架构和应用程序的知识
请参考架构(4)以了解不同的DDD架构风格。另外,应用服务将在应用程序(14)中做 详细讲解。这两个章节都包含了有用的架构框图和代码示例。
限界上下文主要用来封装通用语言和领域对象,但同时它也包含了那些为领 域模型提供交互手段和辅助功能的内容。需要注意的是,对于架构中的每个组件,我们都应该将其放在适当的地方。
白板时间
- 看看白板上的每一个限界上下文,你能想到有哪些非领域模型的组件可以 放在限界上下文之内吗?
- 如果存在用户界面和应用服务,请确保它们是位于上下文边界之内的(要表 示不同的组件,可以参考图2.8、图2.9和图2.10)。
- 如果你的数据库Schema,或者其他持久化存储方案,是根据模型来设计 的,那么请确保它们也是位于上下文边界之内的(要表示数据库Schema,可以参考图2.8、图2.9和图2.10)。
限界上下文的大小
限界上下文中可以包含多少领域模型中的基础部件呢,比如模块(9)、聚合 (10)、领域事件(8)和领域服务(7)等?这好像是在问“一个字符串应该有多长? ”一样。限界上下文应该足够大,以能够表达它所对应的整套通用语言。
核心领域之外的概念不应该包含在限界上下文中。如果一个概念不属于你的 通用语言,那么一开始你就不应该将其引人到模型中。此外,如果有外部概念“偷偷潜入”了你的限界上下文,你需要将其清除,它们可能属于另外的支撑或者通用子域,或者根本就不属于某个模型。
请注意,不要将本应该属于核心域的概念给清除掉了。你的模型应该能够完 全地展现上下文中的通用语言,而不能遗漏任何重要的概念。此时,我们需要做出正确的判断,你可以借助诸如上下文映射图(3)这样的工具。
在电影《莫扎特传》4中有这么一个场景:奥地利皇帝约瑟夫二世告诉莫扎 特,说他刚才演奏的音乐作品很不错,就是音符太多了。莫扎特巧妙地回答道:“我需要的音符正好这么多,一个不多,一个不少。”这种回答也适用于我们现在所讲的限界上下文。限界上下文所包含的领域模型概念应该恰如其分,不多也不少。
4. 猎户座影业,华纳兄弟,1984。 ↩
要做到这一点并不是什么易事,莫扎特可以像给朋友写信一样创作交响乐,而 要创建一个恰到好处的限界上下文就不是这么简单了。任何时候,我们都有可能错失改进领域模型的机会。在每个迭代中,我们都应该对先前的假设提出挑战,这使得我们向模型中添加或删除一些概念,或者改变概念的行为和协作方式等。但是主要的问题是:我们总是面临这样的挑战。在使用DDD原则时,我们会认真地思考应该添加哪些概念,又应该删除哪些概念。使用限界上下文和上下文映射图这样的工具可以帮助我们分析出哪些概念的确应该属于核心域。我们并不随意地采用非DDD的分离原则。
领域模型的优美旋律
如果我们的糢型是音乐,那么它所表现的則是完整性、纯洁性、力量.优雅和美。
如果对限界上下文的限制过于严格,那么我们可能丢失一些上下文概念。相 反,如果向模型中添加过多的概念,我们可能搞不清楚哪些概念是重要的。那么我们的目标是什么呢?如果我们的模型是音乐,那么它应该表现出的是完整性、纯洁性、力量、优雅和美。其中的“音符模块、聚合、事件和服务——的数量正好是设计所要求的那么多。模型的“听众”不会问及到像“为什么中间会有一些奇怪的音符? ”这样的问题。同时,它们也不会因为丢失了某些“音符”而感到不解。
那么,哪些因素会导致我们创建大小不正确的限界上下文呢?我们可能错误 地采用架构来指导设计开发,而不是通用语言。一些平台、框架或者基础设施通常是用来打包和部署组件的,它们可能影响我们对限界上下文的设计,此时我们会从技术层面而不是语义边界来考虑问题。
另一个可能的陷阱是:根据开发任务的分配来拆分限界上下文。技术带头人和 项目经理可能会想,小规模任务对于开发者来说将更加容易完成。这可能是有道理的,但是,为了分配任务而拆分限界上下文是一种错误的上下文建模方式。事实上,我们没有必要为了管理技术资源而创建一些假(fake)的上下文边界。
这里有一个重要的问题:领域专家所采用的语言是如何划定上下文边界的?
如果创建限界上下文只是为了架构组件或开发者资源这样的考虑,那么此时 的通用语言将变得四分五裂,其表达力也会丧失殆尽。因此,我们应该考虑领域专家所讲的通用语言,将核心域中的概念自然地组织成单一的限界上下文。这样一来,你便可以自然地识别出那些单一的、内聚的模型组件。你应该将这些组件放在限界上下文之内。
有时,我们可以使用模块来避免创建一些微小的限界上下文。通过分析分散 在不同限界上下文中的服务,你可能会发现,模块可以将多个限界上下文减少到一个。模块也可以用来拆分开发者的任务职责,因此我们可以使用更加战术化的手段来管理团队的任务分配。
白板时间
- 为你当前的模型绘制一个限界上下文。
即便你还没有一个显式的模型,你也应该从通用语言的角度考虑问题。
- 在这个限界上下文内,填上主要的领域概念的名字。看看你能否发现那些 被遗漏的概念,再看看哪些概念不应该出现在上下文中。对于这两个问题,你会怎么解决?
采用语言驱动来实施DDD时.你得小心
这里的底线是:如果你没有采用语言驱动,那么你就不算在和领域专家一起工作来创 建限界上下文。认真考虑一下限界上下文的大小,不要急于将其小型化。
与技术组件保持一致
将限界上下文想成是技术组件并无大碍,只是我们需要记住:技术组件并不能 定义限界上下文。让我们来看看一些构成和部署限界上下文的常见做法。
当使用丨DE时,比如Eclipse或者IntelliJ IDEA, —个限界上下文通常就是一个 工程项目。当使用Visual Studio和.NET时,在同一个解决方案中将用户界面、应用服务和领域对象分离在不同的子项目中是合理的。项目的源代码可以只包含领域模型,也可以包含一些周边的层(4)或六边形(4)区域等。对于项目的划分是很灵活的。在使用Java时,顶层包名通常表示限界上下文中顶层模块的名字。对于上文中提到的例子,我们可以采用以下方式来定义包名:
com.mycompany.optimalpurchasing
限界上下文的源代码结构可以根据架构职责做进一步分解。下面是一些二级 包名:
com.mycompany.optimalpurchasing.presentation
com.mycompany.optimalpurchasing.application
com.mycompany.optimalpurchasing.domain.model
com.mycompany.optimalpurchasing.infrastructure
请注意,即便存在这种模块化的拆分,团队依然应该只工作在一个限界上下文中。
一个团队,一个限界上下文
将一个团队分配给一个限界上下文并不会限制团队的组织灵活性。这并不是说团队不 能按需安排,也不是说一个团队中的成员不能到其他团队工作。一个公司应该按照实际需要做出人事安排,这意味着我们需要组建一支组织良好的团队,在该团队中,领域专家和开发者只关注于一个限界上下文的通用语言。如果你将多个团队分配给同一个限界上下文,那么每个团队都会使用各自的通用语言,这显然是不好的。
两个团队可能会合作设计一个共享内核,而共享内核并不是一个典型的限界上下文。 这种上下文映射模式使两个团队产生紧密的联系,进而需要两个团队对模型的改变进行不断交流。这种建模方法并不常见,并且我们应该尽量避免这种情况。
在使用iava时,我们可能从技术层面上将一个限界上下文放在一个JAR文件 中,包括WAR或EAR文件。这种做法可能受到了模块化的影响。松耦合的领域模型应该放在不同的JAR文件中,这样我们可以按照版本号对领域模型进行单独部署。对于大型的模型来说,这种做法是非常有用的。将单个大模型分成多个JAR文件也有助于版本管理,比如使用OSGi或者Java 8的Jigsaw模块。因此,不同的高层模块,包括它们的版本和依赖都可以通过捆包/模块(bundles/modules)进行管理。对于上文中的例子,至少存在4个以DDD的二级模块表示的捆包/模块。
对于Windows本地应用程序的限界上下文来说,比如.NET平台,部署可以通 过不同的DLL文件完成。这里我们可以将DLL文件等效于上述的JAR文件,对模型的分离也可以采用相似的方式。所有的公共语言运行时(Common LanguageRuntime, CLR)模块都是通过程序集(Assembly)进行管理的。程序集的版本号和其所依赖程序集的版本号都记录在程序集清单(Assembly Manifest)中。请参考[MSDN Assemblies]。