命令和查询职责分离--CQRS
从资源库中查询所有需要显示的数据是困难的,特别是在需要显示来自不同聚合类型与实例的数据时。领域越复杂,这种困难程度越大。
因此,我们并不期望单单使用资源库来解决这个问题。因为我们需要从不同的资源库获取聚合实例,然后再将这些实例数据组装成一个数据传输对象(DataTransfer Object, DTO) [Fowler, P of EAA]。或者,我们可以在同一个查询中使用特殊的查找方法将不同资源库的数据组合在一起。如果这些办法都不合适,我们可能需要在用户体验上做出妥协,使界面显示生硬地服从于模型的聚合边界。然而,很多人都认为,这种机械式的用户界面从长远看来是不够的。
那么,有没有一种完全不同的方法可以将领域数据映射到界面显示中呢?答案是CQRS (Cammand-Query Responsibility Segregation) [Dahan, CQRS;Nijof, CQRS]。CQRS是将紧缩(Stringent)对象(或者组件)设计原则和命令-查询分离(CQS)应用在架构模式中的结果。
Bertrand Meyer对CQRS模式有以下评述:
一个方法要么是执行某种动作的命令,要么是返回数据的查询,而不能两者皆是。换句话说,问题不应该对答案进行修改。更正式的解释是,一个方法只有在具有参考透明性(referentially transparent)时才能返回数据,此时该方法不会产生副作用。[Wikipedia, CQS]
在对象层面,这意味着:
- 如果一个方法修改了对象的状态,该方法便是一个命令(Command),它不应该返回数据。在Java和C#中,这样的方法应该声明为void。
- 如果一个方法返回了数据,该方法便是一个查询(Query),此时它不应该通过直接的或间接的手段修改对象的状态。在Java和C#中,这样的方法应该以其返回的数据类型进行声明。
这样的指导原则是非常直接明了的,同时具有实践和理论基础作为支撑。但是,在DDD的架构模式中,我们为什么应该使用CQRS呢,又如何使用呢?
在领域模型中一一比如限界上下文(2)中所讨论的领域模型——我们通常会看到同时包含有命令和查询的聚合。同时,我们也经常在资源库中看到不同的查找方法,这些方法对对象属性进行过滤。但是在CQRS中,我们将忽略这些看似常态的情形,我们将通过不同的方式来查询用于显示的数据。
现在,对于同一个模型,考虑将那些纯粹的查询功能从命令功能中分离出来。聚合将不再有查询方法,而只有命令方法。资源库也将变成只有add()或save()方法(分别支持创建和更新操作),同时只有一个查询方法,比如fromId()。这个唯一的查询方法将聚合的身份标识作为参数,然后返回该聚合实例。资源库不能使用其他方法来查询聚合,比如对属性进行过滤等。在将所有查询方法移除之后,我们将此时的模型称为命令模型(Command Model)。但是我们仍然需要向用户显示数据,为此我们将创建第二个模型,该模型专门用于优化查询,我们称之为查询模型(Query Model)。
这不是增加了复杂性吗?
你可能会认为:这种架构风格需要大量的额外工作,我们解决了一些问题,但同时又带来了另外的问题,并且我们需要编写更多的代码。 但无论如何,不要急于否定这种架构。在某些情况下,新增的复杂性是合理的。请记住,CQRSg在解决数据显示复杂性问题,而不是什么絢丽的新风格以使你的简历增光添彩。
其他名字
请注意,在有些情况下,CQRS可以拥有不同的名字。这里的查询模型也被称为读模型,同样,命令模型也被称为写糢型。
因此,领域模型将被一分为二,命令模型和查询模型分开进行存储。最终,我们得到的组件系统如图4.6所示。
CQRS的各个方面
接下来,让我们依次了解CQRS模式的各个方面。我们先从客户端和查询模型开始,再了解命令模型。
客户端和查询处理器
客户端(图4.6最左侧)可以是Web浏览器,也可以是定制开发的桌面应用程序。它们将使用运行在服务器端的一组查询处理器。图4.6并没有显示服务器的架构层次。不管使用什么样的架构层,查询处理器都表示一个只知道如何向数据库执行基本查询(比如SQL)的简单组件。
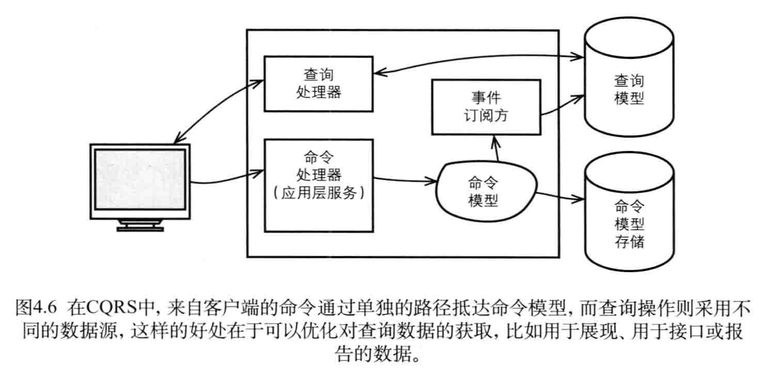
图4.6在CQRS中,来自客户端的命令通过单独的路径抵达命令模型,而查询操作则采用不同的数据源,这样的好处在于可以优化对查询数据的获取,比如用于展现、用于接口或报告的数据。
这里并不存在多么复杂的分层,查询组件至多是对数据存储(比如数据库)进行查询,然后可能将查询结果以某种格式进行序列化。如果客户端运行的是Java或者C#,那么它可以直接对数据库进行查询。然而,这可能需要大量的数据库连接,此时使用数据库连接池则是最佳办法。
如果客户端可以处理数据库结果集(比如■JDBC),此时我们可能不需要对查询结果进行序列化,但我依然建议使用。这里存在两种不同的观点。一种观点是客户直接处理结果集,或者是一些非常基本的序列化数据,比如XML和JSON。另一种观点认为应该将返回数据转换成DTO让客户端处理。这可能只是一个偏好问题,但是任何时候我们引入DTO和DTO组装器(DTO Assembler) [Fowler,P of EAA],系统的复杂性都会随之增加。因此,每个团队应该选择最适合自身的方法。
查询模型(读模型)
查询模型是一种非规范化数据模型,它并不反映领域行为,只是用于数据显示 (也有可能是生成数据报告)。如果数据模型是SQL数据库,那么每张数据库表便是一种数据显示视图,它可以包含很多列,甚至是所显示数据的一个超集。表视图可以通过多张表进行创建,此时每张表代表整个显示数据的一个逻辑子集。
创建足够多的视图
值得一提的是,创建CQRS数据视图可以是非常廉价的,特别是在使用单种形式的事 1件源(Event Sourcing)时(请参考本章后面的“事件源”小节或附录A),此时所有的事件都将被持久化,这样在任何时候我们都可以重新发布显示数据,我们也可以从头重建单个显示视图,或者将整个查询模型转向另外的持久化机制。事件源使我们可以简单地创建和维护显示视图以响应UI变化,这样我们可以在不考虑数据库表结构的前提下获得更直观的用户体验。
比如,要在用户界面上显示用户、经理和管理者等信息,我们纵然可以只创建一张数据库表来包含所有这些信息。但是,如果为每种类型的用户分别创建一个显式视图,我们便可以将每种安全角色的数据进行分离,由此以用户类型为单位来显示安全信息。要显示常规用户信息,我们可以选择该常规用户所对应数据库表视图的所有列;要显示经理信息,我们则可以选择经理所对应数据库表视图的所有列。这样一来,常规用户将不能看到经理用户的数据信息。
此时的选择语句只需要提供数据库表视图的主键即可。下面的SQL语句表示了一个查询处理器选择一种产品的某个常规用户的所有数据列:
SELECT * FROM vw_usr_product WHERE id = ?
顺便提一下,这里使用的表视图命名规范并不值得推荐,但这并不是我们的重点。这里的主键表示某种聚合类型或者多聚合组合类型的唯一标识。在本例中,主键id表示命令模型中某个Product的唯一标识。数据模型的设计应该遵循“一张表对应一种用户界面显示类型”的原则,不同的安全角色应该对应有不同的表视图。但是,我们应该从实际出发,具体情况具体分析。
具体情况具体分析
如果存在25个证券营销人,但是根据SEC规则,他们相互之间都不能看到彼此的销售信息,那么此时我们应该创建25个表视图吗?这里使用一个过滤器可能更加合适,否则我们需要创建太多的表视图。
具体实施起来这可能是困难的,因为我们可能需要将多张表或者多个表视图联合起来查询。联合查询可能是有必要的,或者至少比过滤器更加实用,特别是当领域中存在大量的安全角色时。
数据库的表视图不是会造成重复吗?
在执行更新时,一个基本的数据库表视图是不会产生重复的。一个视图只对应于一个查询,在本例中甚至连联合查询都不会用到。只有具体化(materialized)视图才存在更新重复,因为此时的视图数据需要复制到另外的地方以供选择查询语句使用。在设计数据库表和视图时我们应该多留意,以使对查询模型的更新达到最优化。
客户端驱动命令处理
用户界面客户端向服务器发送命令(或者间接地执行应用服务)以在聚合上执行相应的行为操作,此时的聚合即属于命令模型。提交的命令包含了行为操作的名称和所需参数。命令数据包是一个序列化的方法调用。由于命令模型拥有设计良好的契约和行为,将命令匹配到相应的契约是很直接的事情。
要达到这样的目的,用户界面客户端必须收集到足够的数据以完成命令调用。这表明我们需要慎重考虑用户体验设计,因为用户体验设计需要引导用户如何正确地提交命令,此时最好的方法是使用一种诱导式的,任务驱动式的用户界面设计[Inductive UI],这种方法会把不必要的数据过滤掉,然后执行准确的命令调用。因此,设计出一种演绎式的,能够生成显式命令的用户界面是可能的。
命令处理器
客户端提交的命令将被命令处理器(Command Processor)所接收。命令处理器可以有不同的类型风格,这里我们将分别讨论它们的优缺点。
我们可以使用分类风格(categorized style),此时多个命令处理器位于同一个应用服务中。在这种风格中,我们根据命令类别来实现应用服务。每一个应用服务都拥有多个方法,每个方法处理某种类型的命令。该风格最大的优点是简单。分类风格命令处理器易于理解,创建简单,维护方便。
我们也可以使用专属风格(dedicated style),此时每种命令都对应于某个单独的类,并且该类只有一个方法。这种风格的优点是:每个处理器的职责是单一的,命令处理器之间相互独立,我们可以通过增加处理器种类来处理更多的命令。
专属风格可能发展成为消息风格(messaging style),其中每个命令将通过异步的消息发送到某个命令处理器。消息风格使得每个命令处理器可以处理某种特殊的消息类型,同时我们可以通过增加单种处理器的数量来缓解消息负载。但是,消息风格并不能作为默认的命令处理方式,因为它的设计比其他两种都复杂。因此,我们应该首先考虑使用前两种同步方式的命令处理器,只有在有伸缩性需要的情况下才采用异步方式。可能有人会认为,异步方式可以在不同系统间进行解耦,因此系统具有更高的弹性。这种偏见往往容易导致消息风格命令处理器的产生。
无论采用哪种风格的命令处理器,我们都应该在不同的处理器间进行解耦,不能使一个处理器依赖于另一个处理器。这样,对一种处理器的重新部署不会影响到其他处理器。
命令处理器通常只完成有限的功能。如果处理器拥有创建功能,那么它会创建一个新的聚合实例,然后将该实例添加到资源库中。通常地,命令处理器将从资源库中获取聚合实例,再调用该实例的行为方法:
@Transactional
public void commitBacklogItemToSprint(
String aTenantId, String aBacklogItemId, String aSprintId) {
TenantId tenantId = new TenantId(aTenantId);
BacklogItem backlogItem =
backlogItemRepository.backlogItemOfId(
tenantId, new BacklogItemId(aBacklogItemId));
Sprint sprint = sprintRepository.sprintOfId(
tenantId, new SprintId(aSprintId));
backlogItem.commitTo(sprint);
}
当该命令处理器执行结束后,一个聚合实例将被更新,同时命令模型还将发布一个领域事件。对于更新查询模型来说,这样的领域事件是至关重要的。值得注意的是,就像在领域事件(8)和聚合(10)中所讲,所发布的领域事件还可能导致另一些受同一个命令所影响的聚合实例的同步更新,最终,这些聚合实例都将与本次事务所修改的聚合实例保持最终一致性。
命令模型(写模型)执行业务行为
命令模型上每个方法在执行完成时都将发布领域事件(8)。以Backlogltem为例:
public class BacklogItem extends ConcurrencySafeEntity {
...
public void commitTo(Sprint aSprint) {
...
DomainEventPublisher
.instance()
.publish(new BacklogItemCommitted(
this.tenant(),
this.backlogItemId(),
this.sprintId()));
}
...
}
事件发布器背后是什么?
这里的DomainEventPublisher是一个轻量级的基于观察者(Observer)模式[Gamma etal.]的组件,更多的细节请参考领域事件(8)。
在命令模型更新之后,如果我们希望查询模型也得到相应的更新,那么从命令模型中发布的领域事件便是关键所在。在使用事件源时,领域事件也被用于持久化修改后的聚合(本例中的Backlogltem)。然而,事件源并不一定与CQRS—起使用。除非事件日志包含在业务需求之中,不然命令模型是可以通过ORM等方式进行持久化的。不管如何,我们都需要发布领域事件以更新查询模型。
当命令不发布领域事件
有时,对命令的执行并不会发布领域事件。比如,如果命令是通过“至少一次”的消息进行提交的,而同时应用程序又支持幂等操作,那么重新发出的消息将被忽略掉。 另外,考虑一下当应用程序对命令进行验证的情况。所有的认证客户端都知道命令规则,此时它们将成功通过命令验证。但是,对于那些不知道命令规则的客户端来说——比如恶意攻击方——提交不合法的命令将失败,此时系统将丢弃这些命令。
事件订阅器更新查询模型
一个特殊的事件订阅器用于接收命令模型所发出的所有领域事件。有了领域事件,订阅器会根据命令模型的更改来更新查询模型。这意味着,每种领域事件都应该包含有足够的数据以正确地更新查询模型。
对查询模型的更新应该是同步的呢,还是异步的?这取决于系统的负荷,也有可能取决于查询模型数据库的存储位置。数据的一致性约束和性能需求等因素对此也有很大的影响作用。
如果要同步更新查询模型,查询模型和命令模型通常需要共享一个数据库,这时我们会在同一个事务过程中处理更新。这种方式可以保证两种模型的数据达到完全一致性。但是,这也需要更多的处理时间来更新不同的数据库表,而这有可能会违背服务层协议(service-level agreement, SLA)。如果系统有可能长期处于超负荷状态,并且对查询模型的更新过程又很冗长,那么此时我们应该考虑异步更新。在异步更新中,用户界面有可能无法及时地反映出对命令模型的修改,因此这对最终一致性也带来诸多挑战。更新延迟时间是不可预测的,但是异步更新却有可能满足其他的服务层协议。
有时在创建新的用户界面视图时,我们需要同时创建显示数据。我们可以像前文中提到的那样创建数据库表和表视图,然后通过各种方法将数据添加到新创建的表中。此时,如果命令模型是通过事件源进行持久化的,或者如果存在完整的历史事件存储,那么我们可以回放这些历史事件来更新数据。请注意,只有在适当的事件已经存在的情况下,这种方式才是可用的。否则,只有在今后有新的命令进入系统时,我们才能向数据库表中插入数据。
如果命令模型采用ORM作为持久化机制,那么我们可以用命令模型的数据存储来填充新建的查询模型表。此时我们可以引入常见的数据仓库(或者报表数据库)技术,比如提取-转换-加载(Extract-Transform-Load,ETL)。首先提取出命令模型中的数据,然后按照用户界面所需进行转换,再将转换结果加载到查询模型存储中。
处理具有最终一致性的查询模型
如果查询模型需要满足最终一致性一一即在命令模型更新之后,查询模型会得到相应的异步更新——那么用户界面可能有些额外的问题需要处理。比如,当上一个用户提交命令之后,下一个用户是否能够及时地查看到更新后的查询模型数据?这可能与系统负荷等因数有关。但是,我们最好还是假定:在用户界面所查看到的数据永远都不能与命令模型保持一致。因此,我们需要为最坏的情况考虑。
一种方式是让用户界面临时性的显示先前提交给命令模型的参数,这使得用户可以及时地看到将来对查询模型的改变。这种方式有可能是唯一能够避免用户界面显示陈旧数据的方式。